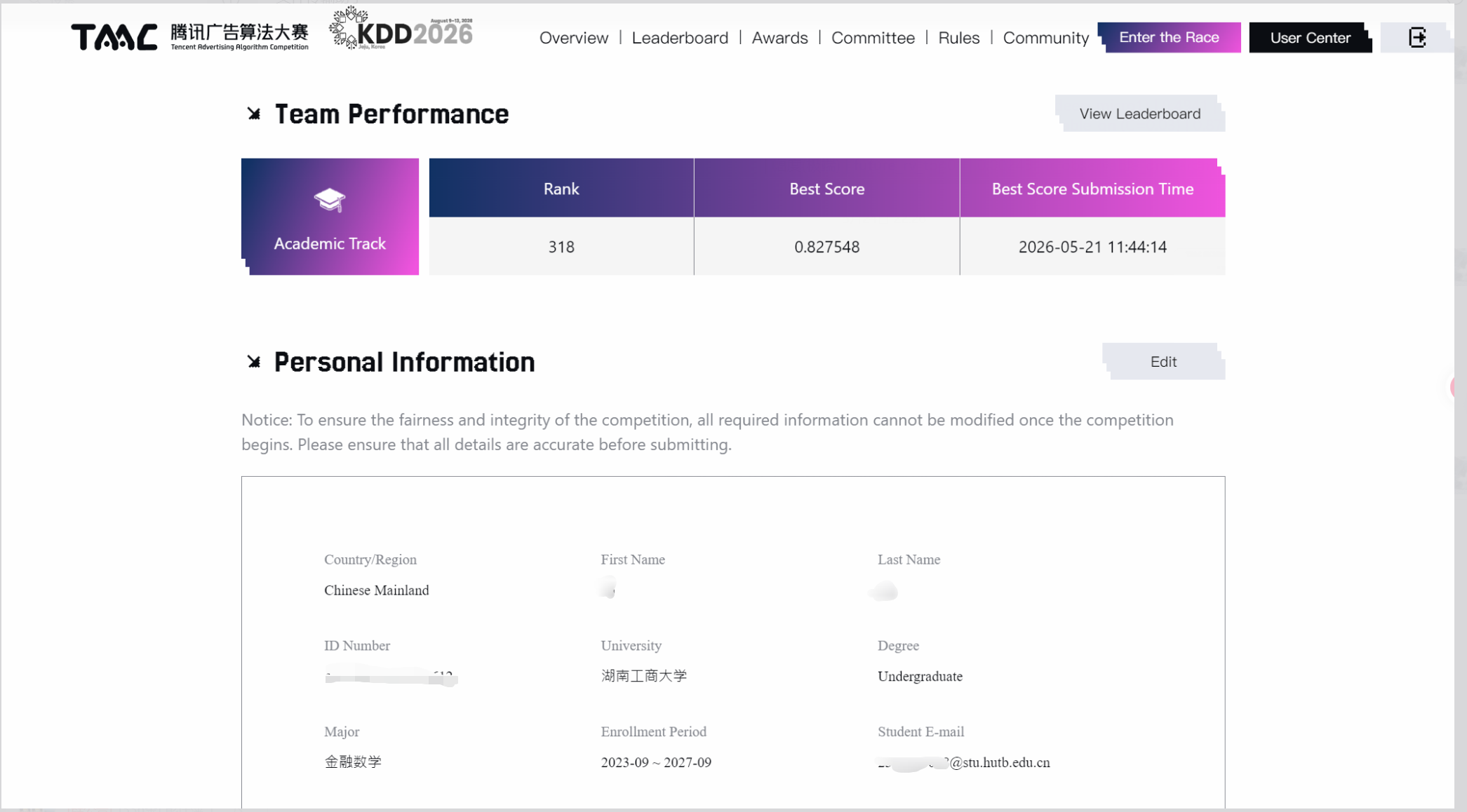
这是我第一次打算法类比赛。在此之前,我更多是在做类似李雅普诺夫稳定性这类非机器学习方向的数学研究。最后我的排名主要在 169 到 352 之间波动,算起来也能说是 top10% 左右。第一次参赛能到这个位置当然不算完全失败,但如果以赛中投入的时间、思考量和最终目标来看,这个成绩并不理想。
比赛结束后,有人开源了 0.83220 和 0.83096 的方案。看完他们的代码和复盘记录以后,很多困扰我很久的问题终于有了答案。这个答案并不华丽,甚至有点刺痛:我不是完全没有判断力,也不是没有找到关键方向。我们找到了时间,找到了 hidden 和 valid 的 gap,也意识到了高基数空间的过拟合风险。但我们真正输掉的地方,是把问题的层级和解题顺序搞反了。
别人先把 baseline 没吃到的数据、loss 和 checkpoint 吃干净,然后才做小结构。我们则太早把问题解释成 hidden gap、复杂架构、门控、消费者行为、低容量、embedding 压缩。很多想法不是错的,但它们出现在了错误的时间点。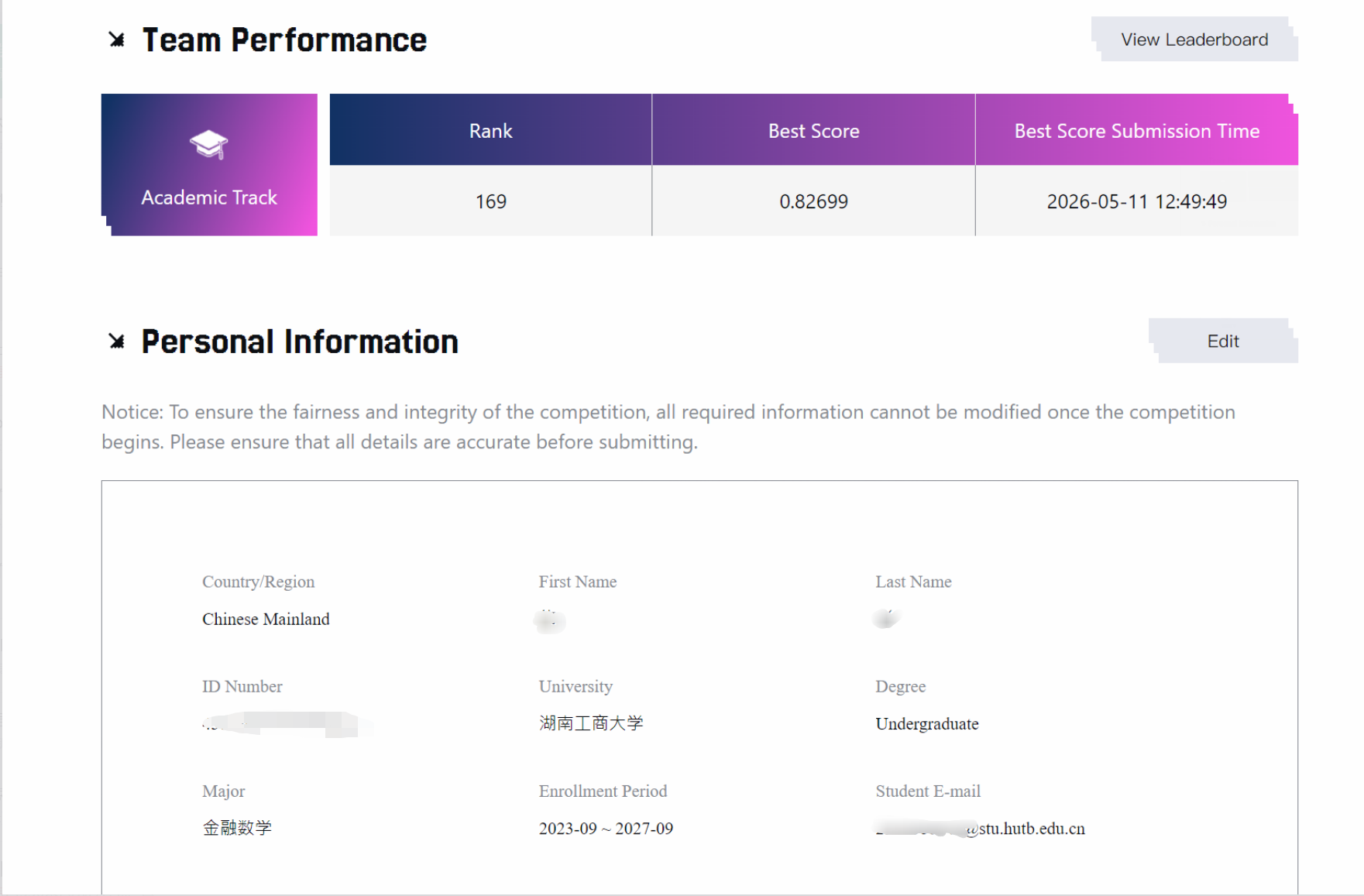
一开始就犯下的工程错误
因为是一个人打比赛,刚开始又不太理解搜推广告算法,所以工程上出现了很多问题,也出现了很多想当然的 idea。想当然不代表不好,只是不适合在比赛最紧张的时候直接使用。
第一个问题是,我没有使用混合精度 AMP 或 BF16 加速训练,损失了比别人多得多的时间。有些开源方案明确使用了 BF16 或 AMP,训练吞吐更好。同样是一天两张卡,我们实际能跑的有效版本数更少。
第二个问题是,在把官方 demo 跑明白之前,我先使用了自己写的简单 baseline。那是一个根据 UniRec 思路写的 Transformer 变体。出于实验习惯,我当时只给一个 batch 做训练,也拿去跑 hidden,结果大致是 0.79x。我一直百思不得其解,后来发现官方 demo 模型在 hidden 上能到 0.81x,于是就直接切到 demo,并开始做机制验证。
现在看,这一步是新手最大的问题之一:我忽视了工程和 baseline 复现,以为特征和想法足够好就一定有好成绩。
比赛不是论文研究。比赛首先要求你复现强 baseline,理解数据和训练协议,然后在这个基础上稳定累计收益。我们一开始没有完成这一步,就急着做机制探索。
我一直在寻找确定性
第二个问题是,我的想法太多,而且没有足够早地理解比赛的本质:比赛不是研究,不是在无限时间内追求最优解释,而是在限定时间内取得更高指标。
第一次打比赛的我,一直在寻找一种确定性。我希望找到某种指标,像控制理论里的 Lyapunov 函数一样,只要它成立,就能保证 local valid 和 online hidden 对齐。为此我写了很多 proxy,包括 cold item、item frequency、timestamp slice、row group tail、sequence length 等多角度指标。
这些 proxy 不是完全没用。它们帮助我们发现了很多事情:
本地 valid AUC 和 hidden AUC 差距很大。
hidden 更像一个特定时间段的数据。
item cold、item frequency 等切片可以帮助判断模型有没有坏掉。
当前样本时间是关键分布坐标。
但问题是,我后来过度相信了 proxy。我希望它解释一切,甚至希望通过 proxy 找到 hidden 上升的充分条件。直到比赛后期我才意识到,本地数据和 hidden 数据的 gap 太大,这些指标根本不能完整解释模型在 hidden 上的变化。
有些时候,两个模型的 cold、item、proxy 都差不多,但 hidden 就是一个上分、一个掉分。有些时候,训练时 cold 和 item 指标甚至不如更早的模型,但 hidden 仍然更高。我不应该一开始就构造一个不可信的 proxy 并把它当成核心目标。proxy 只是辅助手段,不是目的。
我们真正做对的第一件事:时间
我们最重要的正确判断是:时间不是一个普通特征,而是这个赛题里的分布坐标。
一开始我们的 hidden AUC 从 0.78、0.79 慢慢爬升。真正明显的提升来自时间线:
v49 sample time features:hidden AUC
0.823947v52 time conditioned head:hidden AUC
0.824734v53 time Fourier head:hidden AUC
0.826990v91 temporal attention bias:hidden AUC
0.827548
v53 的思路是把当前样本时间以 Fourier/time head 的形式输入模型。v91 更进一步:时间不应该只在最后校准 logit,它应该影响模型如何读取历史序列。也就是说,同样一段历史行为,在不同当前时间下,重要性应该不同。
这条判断赛后看仍然是正确的。开源方案也证明,当前 timestamp 的 day/hour/day-cycle/week-cycle 是最大提分点。我们甚至在机制上把时间推进到了 attention bias,这比很多朴素时间特征更深入。
但我们错在:时间方向刚起效后,没有立刻回到“官方 schema 里还有哪些信息没有被合理吃掉”这个基础问题上,而是开始了越来越复杂的机制探索。
门控:一个理论上很美、实践中没打穿的想法
在比赛后期,我开始不信任单一模型。我注意到,在我的 proxy 下,不同机制在 item、cold、timestamp slice 上的指标并不完全一致。本次比赛不允许融合多个模型,于是我设计了门控专家:一个主专家,加上两个副专家,希望模型自己判断某个样本应该交给哪个机制处理。
这个想法在理论上非常吸引人。经过我的粗略计算,如果 hidden 中错判的样本能被正确送往更擅长的参数区域,我们完全有机会接近 top10 的成绩,而不是 top10%。本质上,这是把 ensemble 的思想内化到一个模型里。
我们做过几条门控线:
v75 mechanism gate:hidden AUC
0.826610v78b mature selective gate:hidden AUC
0.822162v80 selective regime gate:hidden AUC
0.821916v81 regime calibration:hidden AUC
0.823350
结果并不理想。现在看,门控失败不是因为门控思想一定错,而是因为专家不够强、不够互补。我们选的机制更像是一个八边形和两个六边形叠在一起,最后还是接近八边形;也许真正应该做的是找三个三角形,让它们在不同区域有明显强项。
更关键的是,门控本身不是新信息源。没有强专家,gate 只能学习到噪声。门控是锦上添花,不是低垂果实。
时间的本质:思考很深,但落地过早
在门控之后,我开始脑洞大开。我试图思考:我们无法突破 0.83 AUC,是不是因为更底层的模型机制错了?
我甚至开始思考德谟克利特的原子论和芝诺的乌龟悖论,思考时间的本质是什么。时间真的存在吗?模型如何认识时间?对当前模型来说,时间是一个实体,还是只是用于区分过去、现在和未来的语义坐标?我当时区分了“时间”和“时光”:时间是数值坐标,时光是事件在这个坐标上的语义状态。
这个思考并不是完全没价值。v91 的确证明,时间不只是最后的 logit bias,而应该影响历史读取方式。但我们后续把它推得太复杂了。
相关实验大致包括:
v87 consumer intent reader:hidden AUC
0.825953v88 market proto intent:hidden AUC
0.821426v89 temporal evidence router:hidden AUC
0.819666v90 market typed HyFormer:训练完成但没有成为主线
v91 temporal attention bias:hidden AUC
0.827548
最后真正有效的是 v91,而不是更抽象的 market proto 或 temporal evidence router。这说明一个很重要的事情:抽象理论必须落到非常具体的模型接口上。
v91 之所以有效,不是因为它“理解了时间哲学”,而是因为它非常具体地改变了 cross-attention 的读取权重。
市场假设:方向有道理,落点错了
在思考时间本质的同时,我也开始思考:模型如何认识一个消费者?
如果我是一个消费者,我的购买逻辑是什么?年轻女性看到连衣裙,可能更容易购买;中年女性之前浏览过奶粉、小玩具,再看到尿不湿,购买概率可能更高。真实广告转化背后应该有用户画像、商品类型、时间场景、历史兴趣、兴趣衰减和同类物品加成。
于是我们试图从消费者心理学、市场行为、统计学和信息论出发,为模型加入更强的归纳偏置。这个方向听起来很合理,但最终没有明显成功。
相关实验包括:
v86 evidence factorized:hidden AUC
0.816639v87 consumer intent reader:hidden AUC
0.825953v88 market proto intent:hidden AUC
0.821426v93 temporal UE-item pair:hidden AUC
0.825521
现在看,这些市场假设不是错。真实广告系统当然需要用户画像、场景和兴趣。但比赛数据是匿名 schema,我们不能直接建模“年轻女性”“母婴用户”“连衣裙兴趣”,只能通过给定字段逼近这些隐变量。
赛后开源方案告诉我们:市场假设最正确的落点不是手写一个复杂 consumer intent reader,而是识别 user dense 里的语义组。比如 61、87、62-66、89-91 这些 dense 特征,很可能已经承载了用户画像、统计、embedding 或趋势信息。把它们全部拼成一个大 dense 向量过 Linear,相当于把不同来源的用户信息混在一起。
所以市场假设不是错。错的是我们没有先问:数据里哪个字段已经代表市场假设里的中介变量?
过拟合与 embedding 空间:担忧正确,处理太粗
我还思考过是不是模型太大导致过拟合。100 万训练数据喂上亿参数空间,这件事看起来非常危险。训练阶段 AUC 可以到 0.85、0.86,hidden 却只有 0.82x,这似乎也支持“模型记住了训练集”的判断。
我们尝试过低容量模型、embedding 压缩、新架构:
v92 UniRec direct:工程上不够成熟,没有成为主线
v92b UniRec temporal readout:没有明显突破
v94 sparse emb32:hidden AUC 约
0.824293v96 field-aware hash compress:hidden AUC
0.823499v97 v95 epoch4 lock:hidden AUC
0.823358v98 stable query memory residual:hidden AUC
0.824304v99 target time interest reader:hidden AUC
0.819026v100 v91 + low-cap residual:hidden AUC
0.826914
其中 v99 很有意思。它参数少很多,但仍然能超过官方 baseline,说明小模型确实能学到一部分稳定规律。但它没有超过 v91,也说明原 HyFormer 主体确实吃到了一些有效交互。
赛后看,embedding 太大的担忧并非完全错误,但我们处理得太粗。开源高分方案并没有靠粗暴砍 embedding 赢。他们保留了较大的 sparse 空间,只是在输入组织、loss 和 checkpoint 上更合理。正确做法不是“参数大,所以砍”,而是“哪些字段值得保留,哪些字段需要分组、约束或平滑”。
赛后开源方案给出的答案
比赛结束后,我们看了两个开源方案:一个大约 0.83220,一个大约 0.83096。它们的路线非常清楚。
0.83096 方案的主线大致是:
baseline 0.812437
+ global time 0.818828
+ focal loss 0.825397
+ user dense group projector 0.829808
+ step-level checkpoint selection 0.830964
0.83220 方案的主线大致是:
baseline 0.8120
+ focal loss 0.8146
+ day/hour/hour_sin/hour_cos 0.8298
+ candidate anchor + UserDenseGroup 0.8303
+ EMA 0.8322
这两条路线共同说明一件事:0.83 附近的主要收益不是来自重写模型,不是来自复杂 gate,也不是来自低容量替代架构,而是来自四个更朴素的点:
当前样本全局时间特征。
温和 focal loss。
user dense 特征按语义分组建模。
checkpoint 或 EMA 稳定化。
这些东西都在 baseline 周围,并不玄学。真正残酷的是,其中好几个点我们都听说过、讨论过,甚至局部试过,但没有在正确基座上干净累计。
比如 focal。我们在 v65 里把 focal 和 userpair/pair 混在一起测,hidden AUC 0.823211 后就把它一起埋了。现在看,温和 focal 可能是有效的,但我们没有做 “v53/v91 + focal” 的干净实验。
再比如 user dense group。我们做过早期 dense projector,但基座不对。后来没有在 v53/v91 上重新严肃处理 61、87、62-66、89-91。而赛后两个开源方案都说明,这正是核心提分点之一。
我们真正错在哪里
现在回头看,最大的错误不是某一个模型结构写错了,而是解题顺序错了。
我们太早把“baseline 没吃干净数据”解释成“模型架构不够高级”。我们后期反复思考 HyFormer 是否不适合、2 亿参数是否太大、是否要低容量、是否要换 UniRec、是否要更强 reader。可是开源答案表明,到 0.83 这个层级,HyFormer 主体没有错。别人仍然用类似的 RankMixer/HyFormer 主干,仍然是 d_model=64、emb_dim=64、多 epoch 训练。
真正的问题是 baseline 的输入没有吃干净:当前样本时间、user dense 内部语义、训练目标、checkpoint 选择。
这提醒我一件事:当 baseline 很强时,不要急着怀疑 backbone。先怀疑自己有没有读懂数据 schema。
第二个错误是,我们没有把有效信息组织成累计主线。
别人是:
baseline -> time -> focal -> dense group -> checkpoint
我们很多时候是:
v53 -> 一个机制 -> hidden -> 失败 -> 换另一个机制
这样很容易进入排除法。排除法可以减少错误,但很难创造正确答案,尤其当可能的机制空间无限大时。
第三个错误是,我们没有把社交媒体信息转化成干净实验。比赛中途我们已经知道有人提到时间、focal、pair、user dense、UE 分离、checkpoint 波动,但我们没有足够冷静地拆成干净的累计实验,而是经常把多个机制混在一起。
如果重来一次
如果带着赛后答案重打一遍,我会把顺序改成这样:
先完全复现官方 baseline 的长训练结果,不急着改模型。
立刻加入当前样本时间特征:hour/day/week/cycle。
在时间基座上干净调 focal,尤其是温和 gamma。
系统审计 schema,重点拆 user dense:
61、87、62-66、89-91。加 step-level validation 或 dense-only EMA,减少 checkpoint 噪声。
在上述主线吃完后,再考虑 temporal attention bias、candidate anchor、gate 或更复杂架构。
也就是说,v91 不是不该做。v91 应该出现在更晚的位置:在 time + focal + user dense group + EMA 之后,而不是替代这些基础收益。
这次比赛给我的教训
这次 TAAC 因为诸多原因没有取得理想成绩,但它给我的经验非常深。
第一,比赛和研究不一样。研究可以追求解释,比赛先追求可累计的收益。
第二,强 baseline 赛题里,最先要做的不是发明新结构,而是审计 baseline 到底漏吃了哪些数据。
第三,理论想法必须落到字段、loss、checkpoint 和训练协议上。当一个想法无法回答“它具体吃哪个字段、修哪个输入、改变哪个梯度、稳定哪个 checkpoint”时,它可能仍然深刻,但还不够工程化。
第四,proxy 是辅助,不是信仰。它可以告诉你模型有没有坏掉,但不能保证 hidden 一定涨。
第五,复杂机制不是不能做,而是要等基础主线吃干净以后再做。没有强专家,gate 学不到什么;没有明确字段语义,市场假设只能停留在想象;没有稳定 checkpoint,很多小收益都会被训练噪声淹没。
最后,如果要用一句话总结这次比赛:
我不是输在没有想法,而是输在想法太早离开了数据。
这也是这次复盘最有价值的地方。以后再打类似比赛,我会更早、更冷静地回到数据 schema、baseline、训练协议和可累计主线,而不是在还没吃完低垂果实时,就急着解释整个世界。